Organization
Core
Python was selected due to its status as the most prominent programming language for data science. Given the extensive range of available packages, it proved to be the most effective language for our problem.
The PyMuPDF library was employed for the extraction of data from PDF documents, as it is the most high-performance Python library for this purpose.
spaCy is a high quality package for natural language processing tasks. We chose to work with spaCy because it provides many components without much configuration.
Python LLM provides a simple API to wrap around the many existing large language models.
Web View
- HTML
- JavaScript
- CSS
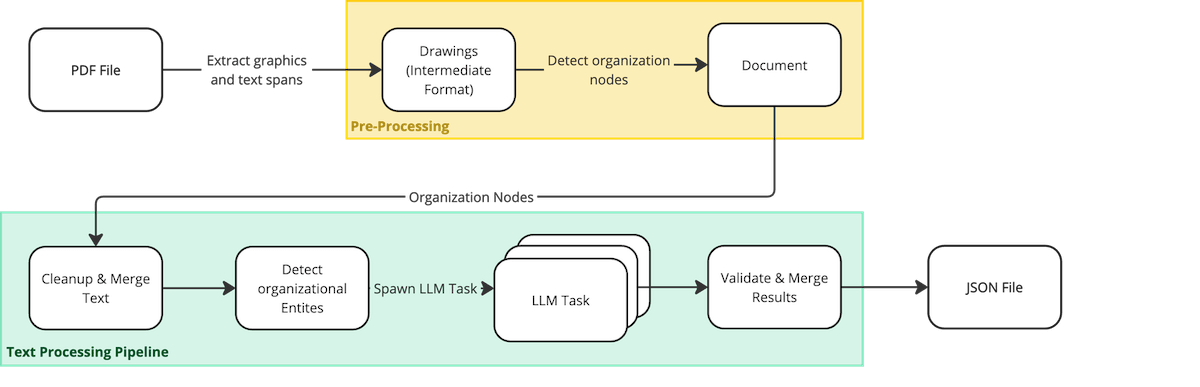
Project Architecture