With medical apps it is especially important that they are based on scientific research.
We started by researching about Long Covid: How is the illness defined? How is it diagnosed?
Which are possible symptoms, which are most common and how are they treated?
How frequent is Long Covid? What could be the cause of Long Covid? What do Long Covid patients wish for?
Additionally, we read personal reports published by patients of Long Covid on
social media platforms like Instagram or Tumblr. Although not scientific, these reports helped us
get insights into the every day life, fears and wishes of patients.
Personas
From our combined research we extracted four personas. Here is a short summary for each of them.
Sonja Sorgenvoll, 50, baker, recovered from Covid-19: “Do I have Long Covid or am I just going crazy?”
Franz Frustriert, 22, student, Long Covid patient: “I’m sick of feeling so helpless. Suffering from brain fog I can’t even focus on my studies anymore.”
Nils Nichternstgenommen, 30, teacher, Long Covid patient: “My colleagues don’t take me seriousely. I just feel alone with Long Covid.”
Mona Motiviert, 40, project manager, Long Covid patient: “I won’t let Long Covid get me down. What can I do to get well soon?”
User Stories
We collected the problems that our personas have and developed User Stories from them.
Those we clustered into five main topics and prioritized them. Here are those User Stories that we focused on:
information:
As a patient of Long Covid I want to read about current scientific recommendations on how to handle Long Covid
As a patient of Long Covid I want to see easily understandable explanations on symptoms so I can better explain myself
tracking:
As a patient of Long Covid I want to track my symptoms to get an overview over my symptoms and communicate them
As a patient of Long Covid I want to be reminded about positive development to stay motivated
As a patient I want to be notified when I should see a doctor
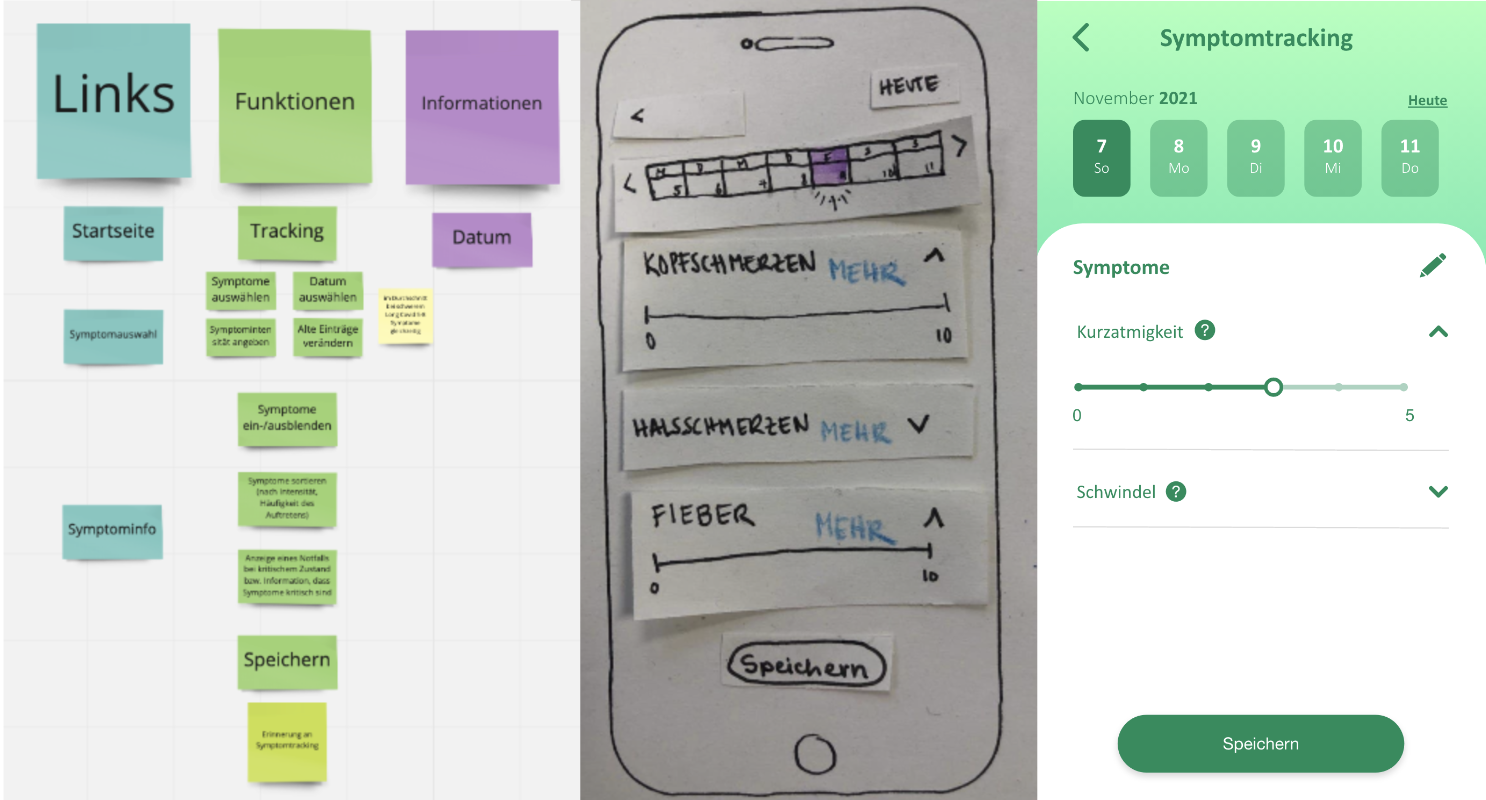
Prototyping
After deciding on all the features we figured out the different screens the app should have and which functionalities,
information and links should be presented on it. From there we created a paper prototype for the app.
Next we created a second prototype in Adobe XD for the visual design and user experience. We tried out different design ideas and
decided to go with a green theme and color gradients.
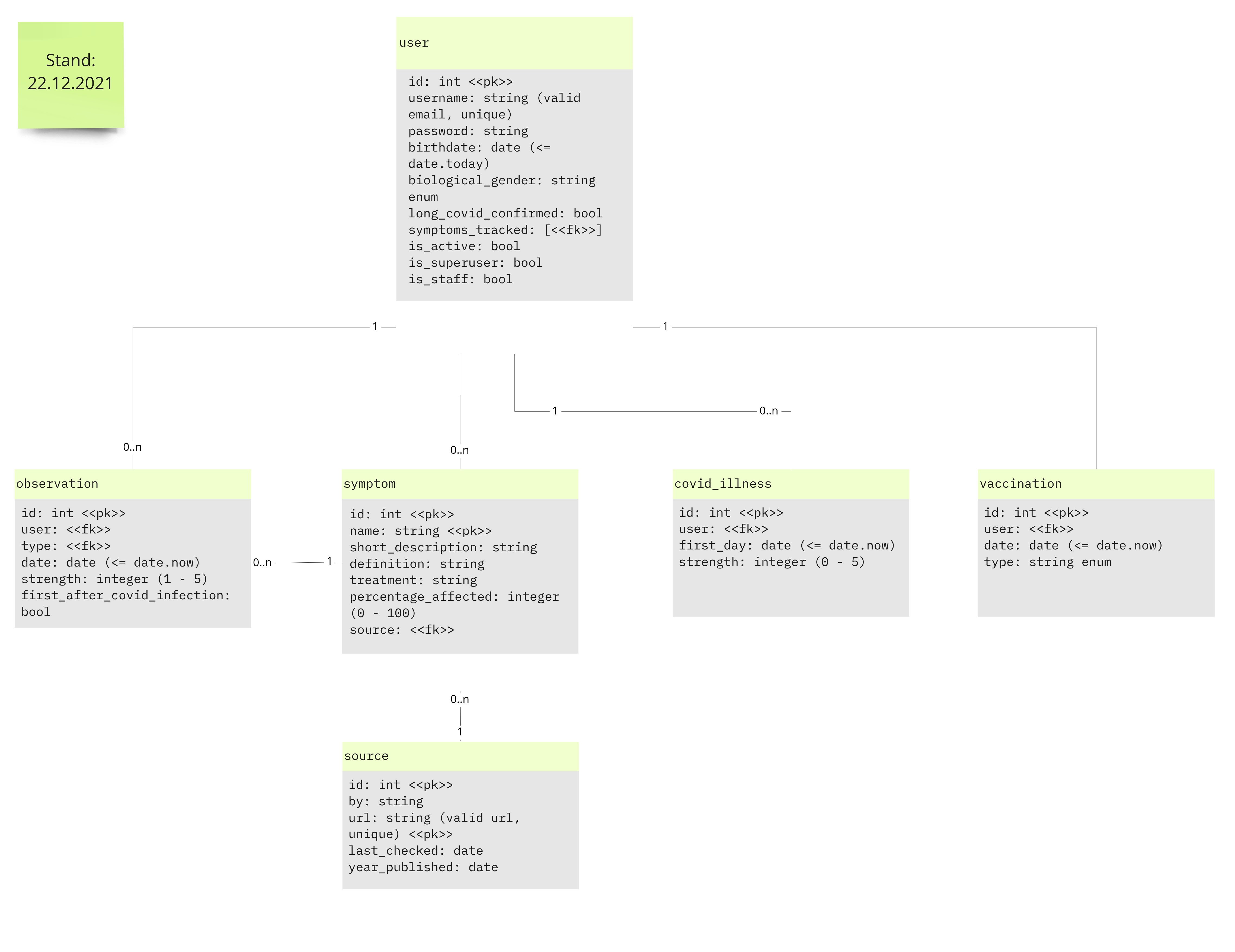
Data Model
Based on our features we designed the following data model.
Implementation and Workflow
Backend
When developing the backend we first set up a regular Django app, adding PostgreSQL as a database.
Building upon the Django template app we extended views and serializers to change default behavior and add authorization.
For example, in order to save a password, it had to first be extracted from the sent request data and hashed before it
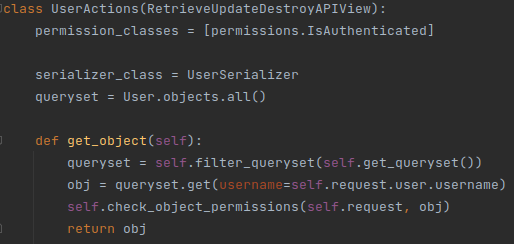
could be handed to the serializer together with the remaining validated data. Or, in the example below, the UserAction
view extends DRF’s “RetrieveUpdateDestroyAPIView” by overriding the “get_object” method so that users may only get,
patch or delete their own user object.
We almost always applied the method of test driven development. Step by step we created 62 tests for registration, authentication,
authorization and all endpoints.
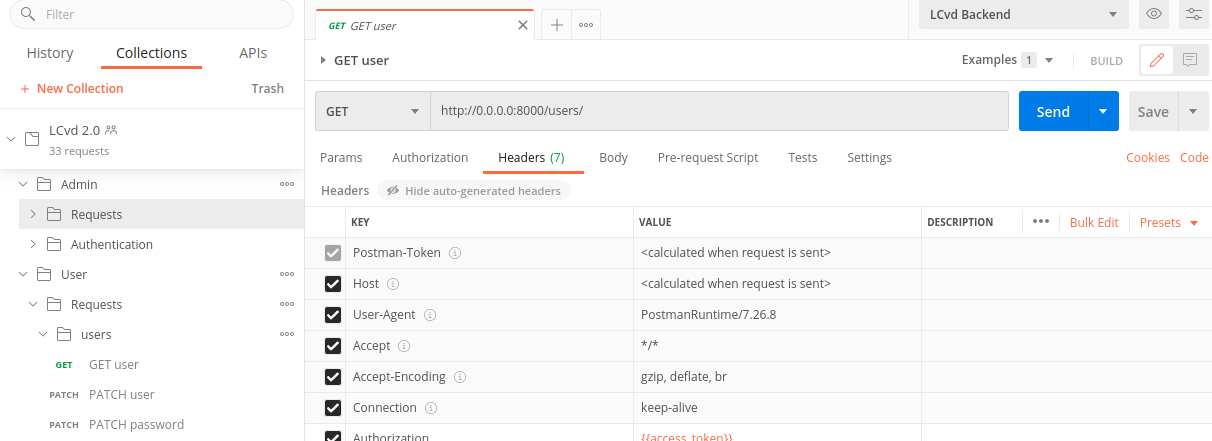
In parallel, we used a shared Postman collection to document the API endpoints.
Postman collections can be shared with a workspace, where they can then be edited together. However, the free version of
Postman has a member limit on workspaces, which is why some team members needed to import (and re-import after an update)
the statically shared collection. We created pre-request scripts to allow for Postman requests to be run independently.
These pre-request scripts for example create and log in with a user, store access tokens in an environment for later use in request
headers and create various test data.
Right from the start, our goal was to make the backend as easily usable as possible for the frontend developers: all team members
should be able to easily develop or use the backend, without worrying how to set it up and install requirements,
no matter which system they use. While Docker worked well on Linux and macOS, it turned out to be difficult to use with Windows.
So before starting to implement any features we dockerized the backend. Dockerizing Django apps is not straightforward.
For making migrations and creating a superuser, one would need to open the shell inside a Docker container,
which is too much work to do everytime. So we
created an entrypoint script for these jobs that runs everytime the containers are started. A challenge was that the
commands for creating a superuser and making migrations could not take user input in the entrypoint script, so all parameters
needed to be set in different ways, eg. in the Django “settings.py”-file.
Deployment
When the development of the backend was almost complete we deployed it to a Debian server with Nginx as a web server and Gunicorn
as the application server. Since we didn’t use Docker for production we had to replace the entrypoint script that makes
migrations and creates a superuser with two slightly modified bash scripts:
one to initialize the backend on the server by creating a superuser and installing data fixture
one that makes migrations and starts the virtual environment and Gunicorn.
The latter script is run by the “backend” service that we created on the Debian server and is re-run to restart the application
server whenever it is stopped.
In the frontend for our iOS and Android app we started out by setting up NativeScript and a basic NativeScript-Vue app.
We then began implementing the most important views: the calendar, tracker, signup and login and visualization.
Once the login was available in the backend we began implementing the requests to the backend and managing the application
state with Vuex. We also made sure to save the JWT in the Application Settings, so that users won’t have to log in again after
reopening the app. After all the requests were finished, we started working on the rest of the views.
With NativeScript it is not possible to use HTML-Elements in the template, since the app is not run in a browser but in a native environment.
Therefore the use of NativeScript-Elements is imperative which create a wrapper for the native UI Components of Android and iOS.
This can be challenging since for some elements there are differences between Android and iOS that need to be accounted for and
some of them can’t be resolved by different styling. Another challenge is that not all the features are documented well or the
documentation pages seem to be unavailable.
This was also the case for the visualization which we wanted to create by using the NativeScript UI Charts. This turned out to be
very difficult since the documentation on it was so spare. After working on it for a while and figuring out the details of how to use it
ourselves, we realized that the features where not enough to achieve the visualization we had imagined. Therefore, we had to find another way.
Using a WebView we were able to create the visualization with the JavaScript library Chart.js. The data for the visualization is passed using the src of the WebView.
The variable webViewSrc is bound to the src of the WebView, so every time the variable changes the WebView reloads with the new data that is passed as stringified JSON in the src.
In the HTML-File that creates the visualization the data can then be parsed to a JavaScript object again.