In this Part of the project we implemented a reinforcement learning algorithm that would be able to solve the pathfinding problem. In addition to supervised and unsupervised learning, reinforcement learning is one of the three pillars of machine learning. In contrast to supervised, reinforcement learning does not have any labeled training data. The training process is relatable to how humans and animals learn. It is a combination of trying out and applying knowledge gained. Basically, reinforcement learning consists of an agent who works in an environment, much like a mouse in a maze. The mouse has to find a way to the end of the maze and can find something to eat as a reward. The longer the mouse explores the maze, the more experience it gains and the faster and more error-free it finishes subsequent runs.
Like all reinforcement learning algorithms, ours has the essential components that are needed. Firstly the environment that contains information about the state and all the rules of how to move inside the world and how to calculate the rewards. Rewards are a numerical value, which qualify the actions taken. In the first implementation the world was also part of the environment, but we figured out that only the position of the agent is vital. The world never changes its voxels, so it does not need to be stored. Secondly the agent, who interacts with the environment and gets rewards depending on the actions taken.
While in training, the environment gets an action. Each action received is called a step and all steps, accumulated until some break up criteria are met, are called an episode. Before the action gets executed, it gets examined. If the action leads to an invalid state, then the action is denied, the episode will be ended, a final reward is calculated and the environment will reset to its original state. If the action is valid, then the action is executed, the state will be updated, and a reward is calculated and accumulated to the previous rewards of this episode.
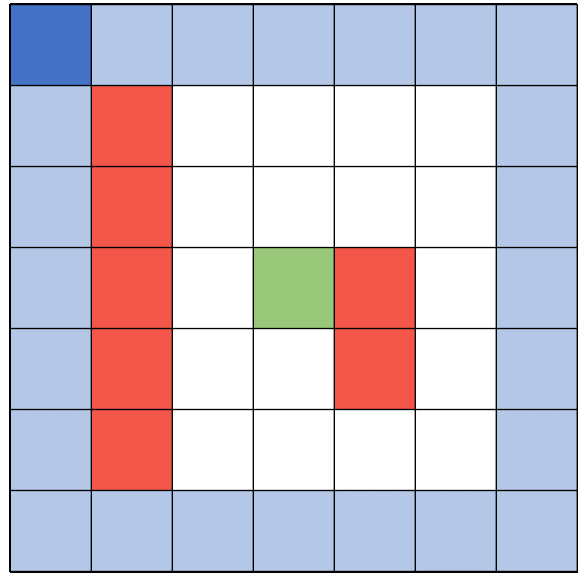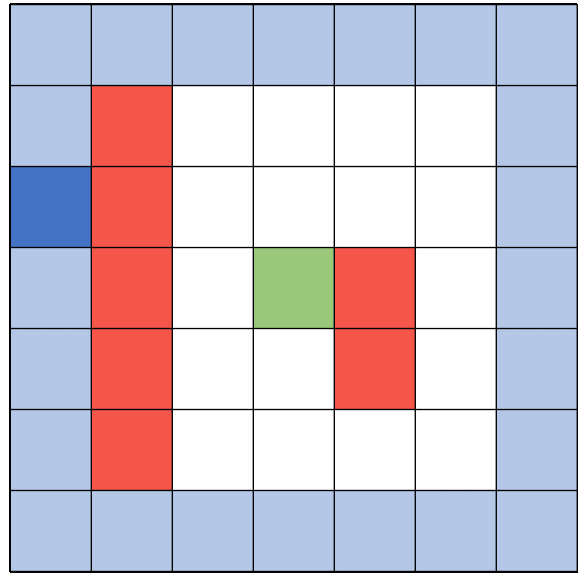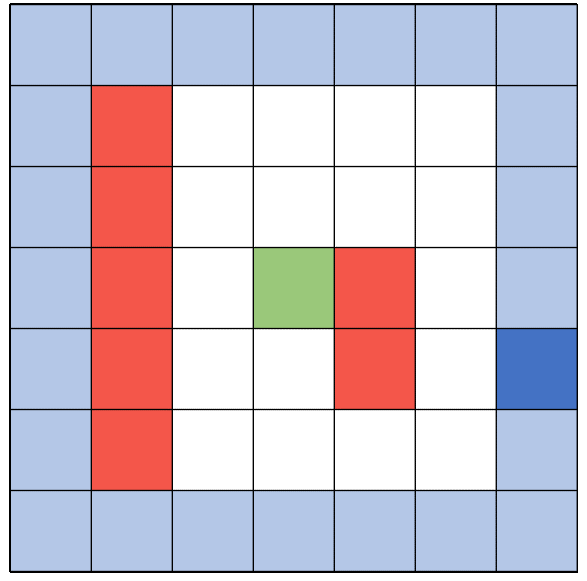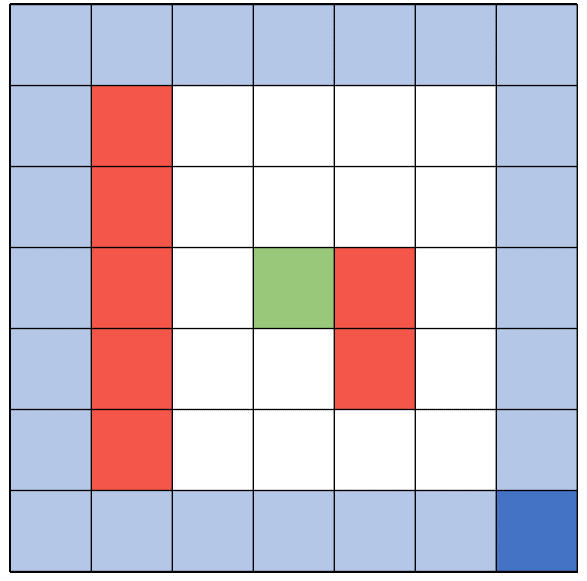
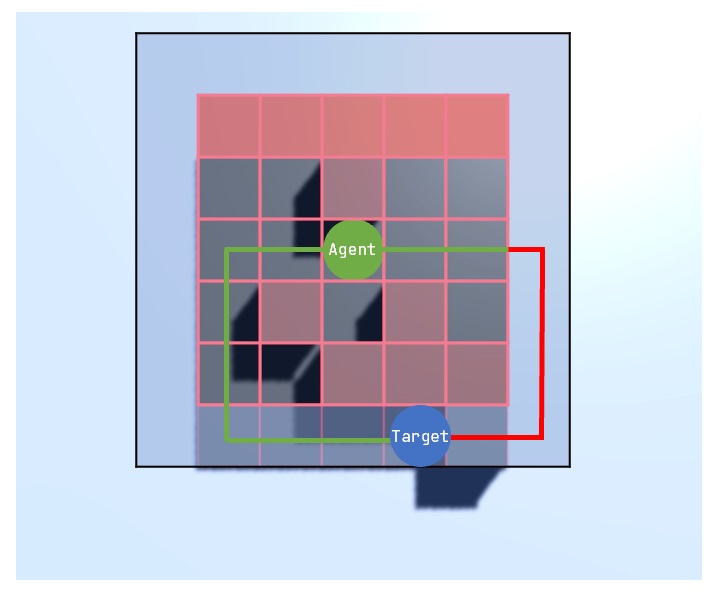
There are 4 ways in total how an episode can be ended. First of all, with an illegal move, like walking into a wall. A second option is reaching the goal. The third way is reaching the maximum number of steps allowed per episode. The last to trigger the end is reaching the minimum reward cap.
Each action has a corresponding reward depending on the state of the environment. Walking into a wall gives a highly negative reward - while walking in general gives a very minor negative reward. This shall encourage the agent to find the shortest path. Another minor negative reward is given when the agent walks onto a cell which was already visited in this episode. Lastly there is a negative reward given depending on the general distance to the target. The closer the agent is to the target, the smaller is the negative reward. Moving onto the target cell is the only positive reward the agent can get.
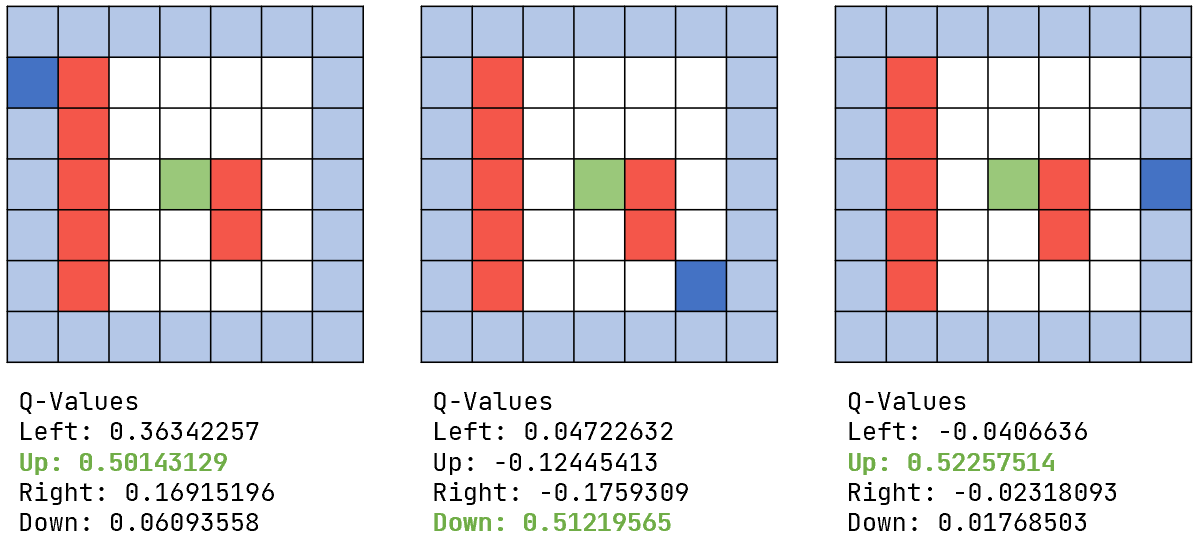
One integral part of Reinforcement Learning is the Q-Net. This Q-Net is a deep neural network which contains Q-Values which are calculated from the relation of state, action and reward. Its main purpose is to provide information for the markov decision process, which in return selects the optimal action to maximize the reward for all subsequent steps in an episode. While in training, the Q-Net gets updated with experiences from the replay buffer and an optimizer to minimize a cost function.
The replay buffer is a list in which every finished episode is stored, while in training, some of the episodes inside the replaybuffer are then selected and used to update the policy of the agent.
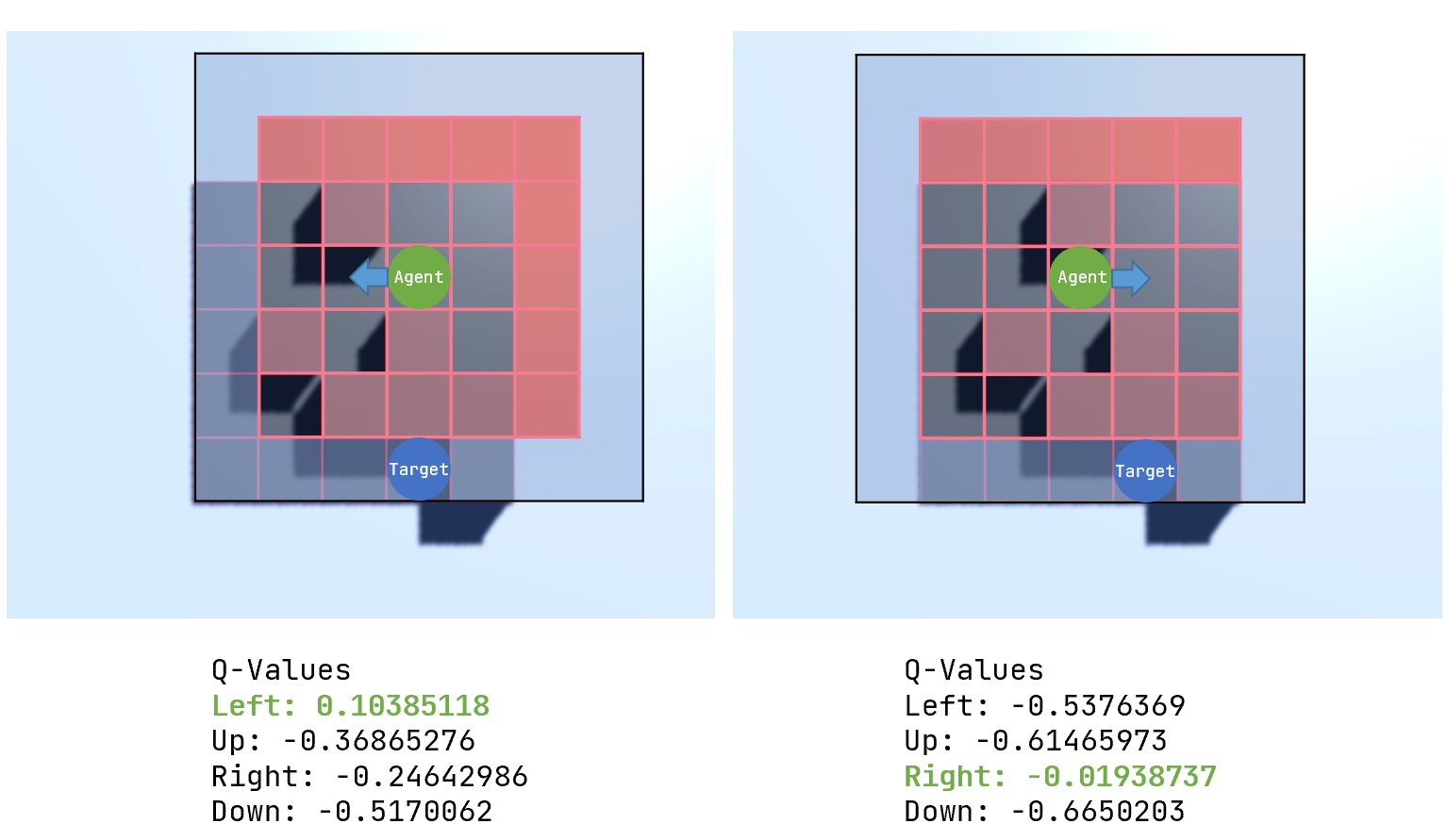
A policy is a strategy that the agent uses to accomplish its task. Based on the experiences learned, the policy dictates how the agent behaves under certain conditions. Conditions in this project would be the position of the agent.
The optimizer used in this project is the ADAM optimizer, adaptive moment estimation, which is an extension of the SGD algorithm, stochastic gradient descent.
The agent is the entity which is interacting with the environment. It contains the Q-Net, an optimizer and a loss function. There are two types of agents which are in use. The first is a DQN-agent, which has a deep neural network instead of plain Q-table, which is used in Q-learning and it is trained with episodes of the replay buffer. The Other is a DDQN-agent, which uses two identical deep neural networks.
While in training there are two different modi on how an action is selected. Exploring, the agent gets random actions without using its knowledge and it is mainly used in the beginning of the training. This eventually leads to new paths and prevents the agent from getting stuck. Later on the agent will rely more on the exploitation and uses the accumulated knowledge to improve the paths found so far.
Many different hyperparameters can be tuned for the training process. The epsilon value, discount factor, learning rate, size of the replaybuffer, number of episodes, number of steps per episode, number of neural network layers, number of nodes for the layers and the values for the individual rewards.
The epsilon value expresses the ratio of exploration to exploitation. A value of 0.1 means that in one out of ten episodes the agent gets random actions. The discount factor, a value between zero and one, describes whether the agent is more long term or short term oriented. The learning rate represents how much the Q-net gets updated in each iteration. A value of zero would indicate no learning at all and a value of one overrides old Q-Values with the new ones. Finding the optimal set of hyperparameters is very complex because the training involves a lot of randomness during the exploration phase. A direct before and after comparison is not always meaningful because of this.
Our setup is based on Tensorflow and it’s TF-Agents library. It provides a lot of performant modular solutions to implement reinforcement learning projects. The most positive aspect is the significant speed boost in training an agent, which is due to how Tensorflow works and how efficiently it processes its datastreams. If the correct version of it is installed, the Nvidia CUDA toolkit is automatically used to accelerate the training process using the available GPU resources.



{kind=link}