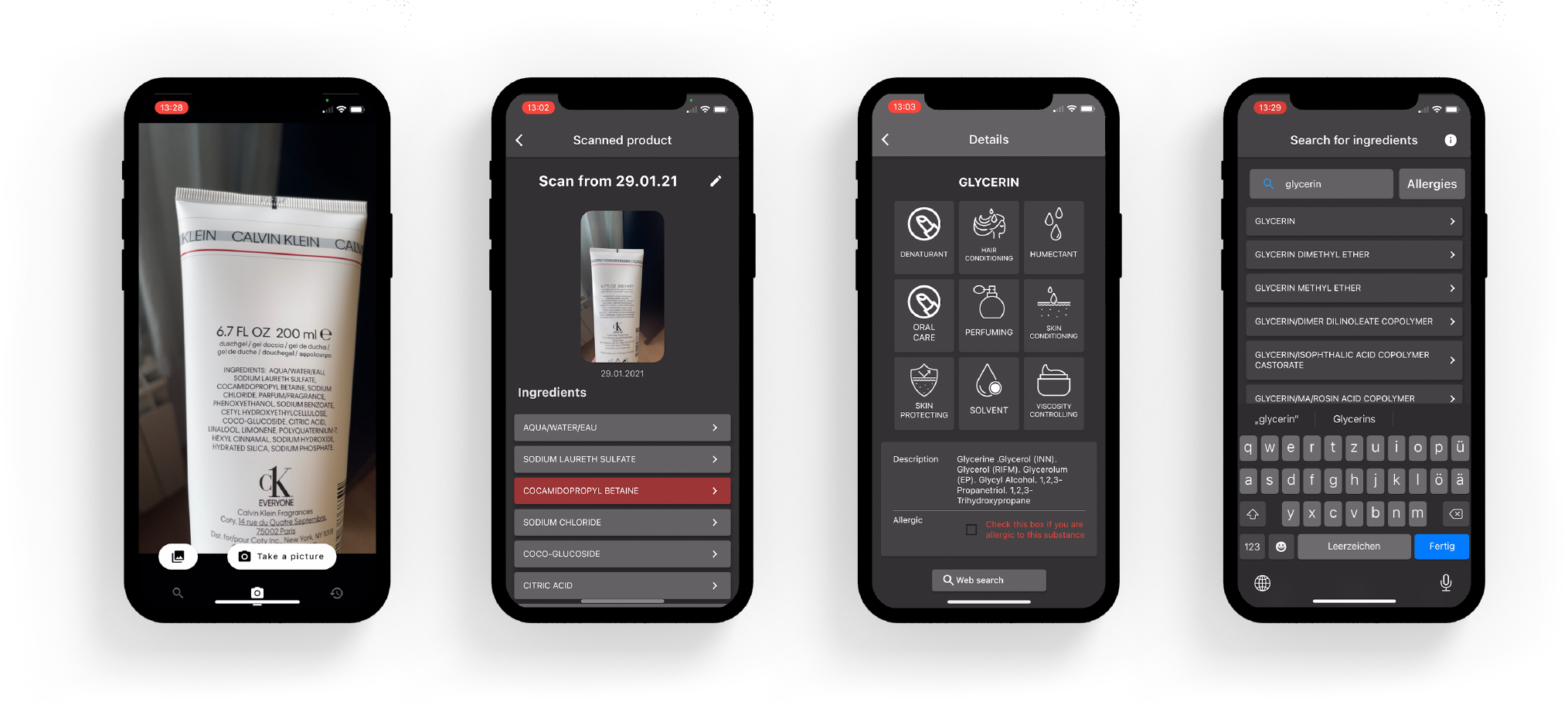
Offline Data
Our app is completely offline compatible. We have over 30.000 ingredients stored in our data set. It was important for us to guarantee that the user is always able to use the app. Therefore we didn’t want to rely on an internet connection.
Text Recognition/Filtering
Our app uses the Firebase ML text recognition to recognise the ingredients on the back of the product.
The backside of a product is full of information that isn’t interesting to us or our app. So filtering out the information we need was quite important for the performance of our app. Some things that our app takes into account is how the ingredients are separated. It differs from product to product how they separate the ingredients, some use commas, some use dashes, some just use spaces. For our app to scan products as fast as possible, we need to recognise which word is an ingredient and which isn’t, so our search algorithm doesn’t have to search for words that aren’t ingredients. Another way to improve our text filter was to look for the word ‘ingredients’ or variations of it. In most cases, the list of ingredients starts with the word ‘ingredients’, so finding this word in our text helped us locate the list of ingredients in our scanned text.
Allergies
One of our core features is the allergy feature. This feature derived from one of our User Personas that we created for our app. People with allergies can use our app to manage them and use it as a signal for whenever they are about to buy a product they are allergic to.