This is the first IMI Showtime for some of our group members. In general, we knew what was ahead of us to reach our newly shared goals. After kicking off the project and getting to know each member’s strengths and preferences in the scope of the project, as well as our supervisor’s visions, we excitingly head on moved to the brainstorm and research phase. Tools such as Miro and the Gitlab board were of great help to manage the ideas and visuals. In this phase, we clarified questions, collected functional ideas from each member, talked about available technologies and initial visuals of the application. In addition, one of the core tasks was to conduct data research, which was lead by our supervisor Marco A. Afterwards we had to make decisions about our chosen tech stack. We defined functional and non-functional requirements, as well as visions and goals. A low-fidelity design had been prepared to visualise the ideas resulting from the brainstorming sessions. Finally, the last step of the overall preparation phase was to acquire the necessary knowledge and missing data to initiate the development. At that point, the preferences of each team member were clear, thus the team was separated into two sub-groups: Frontend (consisting of Mischa, Malin and Nhu) and Backend (consisting of Cyrine and The-Anh).
Strengths and preferences
To get to know each team member, we documented everyone’s skills and likings in a ticket in GitLab. This really helped us find correlations to common skills within the team to later decide on the tech stack. The teams were also separated based on everyone’s interests.
Research
Researching was one of our core task (see section “Research” below).
Brainstorming
The first five meetings were mainly about forming a common goal and a shared view within the team. We kicked off with a brainstorming session in which various ideas were introduced and elaborated on. Results from the sessions were documented in our Miro board and in the related ticket in GitLab. Topics which were of importance for the decision making:
Functional and non-function requirements
Frontend: Desktop-first or mobile-first? Colour palette? What kind of user experience do we want to make? What should the feel and look be like? Which elements of gamification can we make use of? What technologies do we want to use?
Backend: What does our data model look like? Machine learning or expert engine? Which strategy will be used? Which logic should we decide on, fuzzy logic or bayes theorem?

Miro board: UI ideas and Inspiration board
Decision making
- Tech Stack & Functional and non-function requirements
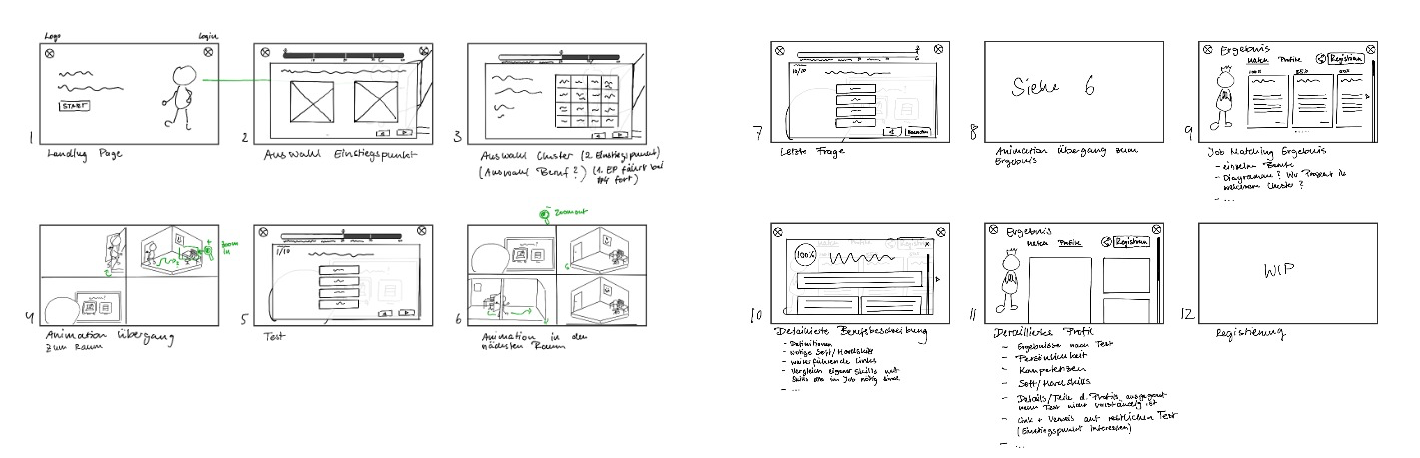
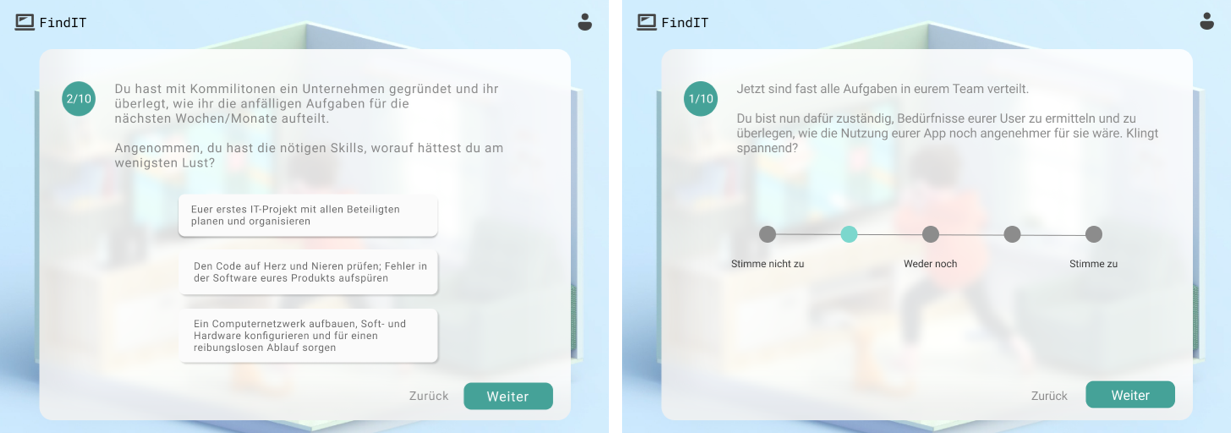
- User Interface: The results from our brainstorming sessions were screen sketches and a storyboard for the animation (see section “Sketches & Storyboard” below), as well as a high-fidility design (see section “High-fidility Design” below), which has been created afterwards. The functional and non-functional requirements have been documented in GitLab.
- Expert System: Further results from our brainstorm session was a draft of an expert system that works with heuristics (see section “Artificial intelligence engine” below)
Aquire missing knowledge
In the last step of the preparation phase, we acquired the needed knowledge as quick as possible. There were a lot of technologies, which were new to us.